
一、命令的详情
1、 功能的说明
grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹 配的行打印出来。grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。
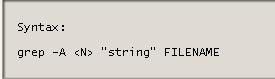
2、 语法格式
grep {OPTIONS} PATTERN {FILE}
参数 匹配模式 查找文件
grep命令里的匹配模式,都是你要的内容,可以用普通字符或者正则
3、选项说明
-a --text #不要忽略二进制的数据。 -A<显示行数> --after-context=<显示行数> #除了显示符合范本样式的那一列之外,并显示该行之后的内容。 -b --byte-offset #在显示符合样式的那一行之前,标示出该行第一个字符的编号。 -B<显示行数> --before-context=<显示行数> #除了显示符合样式的那一行之外,并显示该行之前的内容。 -c --count #计算符合样式的列数。 -C<显示行数> --context=<显示行数>或-<显示行数> #除了显示符合样式的那一行之外,并显示该行之前后的内容。 -d <动作> --directories=<动作> #当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。 -e<范本样式> --regexp=<范本样式> #指定字符串做为查找文件内容的样式。 -E --extended-regexp #将样式为延伸的普通表示法来使用。 -f<规则文件> --file=<规则文件> #指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。 -F --fixed-regexp #将样式视为固定字符串的列表。 -G --basic-regexp #将样式视为普通的表示法来使用。 -h --no-filename #在显示符合样式的那一行之前,不标示该行所属的文件名称。 -H --with-filename #在显示符合样式的那一行之前,表示该行所属的文件名称。 -i --ignore-case #忽略字符大小写的差别。 -l --file-with-matches #列出文件内容符合指定的样式的文件名称。 -L --files-without-match #列出文件内容不符合指定的样式的文件名称。 -n --line-number #在显示符合样式的那一行之前,标示出该行的列数编号。 -q --quiet或--silent #不显示任何信息。 -r --recursive #此参数的效果和指定“-d recurse”参数相同。 -s --no-messages #不显示错误信息。 -v --revert-match #显示不包含匹配文本的所有行。 -V --version #显示版本信息。 -w --word-regexp #只显示全字符合的列。 -x --line-regexp #只显示全列符合的列。 -y #此参数的效果和指定“-i”参数相同。
简单的示例
1、在大部分的场景中我们需要获得本机的网卡的IP
[root@92fuge ~]# ifconfig eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 10.0.0.7 netmask 255.255.255.0 broadcast 10.0.0.255 inet6 fe80::20c:29ff:fed8:2d2d prefixlen 64 scopeid 0x20<link> ether 00:0c:29:d8:2d:2d txqueuelen 1000 (Ethernet) RX packets 17826 bytes 18730622 (17.8 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 8133 bytes 683795 (667.7 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 eth1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 172.16.1.7 netmask 255.255.255.0 broadcast 172.16.1.255 inet6 fe80::20c:29ff:fed8:2d37 prefixlen 64 scopeid 0x20<link> ether 00:0c:29:d8:2d:37 txqueuelen 1000 (Ethernet) RX packets 9 bytes 540 (540.0 B) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 38 bytes 2802 (2.7 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536 inet 127.0.0.1 netmask 255.0.0.0 inet6 ::1 prefixlen 128 scopeid 0x10<host> loop txqueuelen 0 (Local Loopback) RX packets 0 bytes 0 (0.0 B) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 0 bytes 0 (0.0 B) TX errors 0 dropped 0 overruns 0 carrier 0 collisions
操作取IP 的命令
[root@92fuge ~]# ifconfig eth1 |grep -Po "[\d.]+(?= netmask)" 172.16.1.7 [root@92fuge ~]# ifconfig eth0 |grep -Po "[\d.]+(?= netmask)" 10.0.0.7
3 、 去除nginx配置文件的注释和空行
[root@92fuge ~]# cat /etc/nginx/nginx.conf
# For more information on configuration, see:
# * Official English Documentation: http://nginx.org/en/docs/
# * Official Russian Documentation: http://nginx.org/ru/docs/
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log;
pid /run/nginx.pid;
# Load dynamic modules. See /usr/share/nginx/README.dynamic.
include /usr/share/nginx/modules/*.conf;
events {
worker_connections 1024;
}
http {
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
types_hash_max_size 2048;
include /etc/nginx/mime.types;
default_type application/octet-stream;
# Load modular configuration files from the /etc/nginx/conf.d directory.
# See http://nginx.org/en/docs/ngx_core_module.html#include
# for more information.
include /etc/nginx/conf.d/*.conf;
server {
listen 80 default_server;
listen [::]:80 default_server;
server_name _;
root /usr/share/nginx/html;
# Load configuration files for the default server block.
include /etc/nginx/default.d/*.conf;
location / {
}
error_page 404 /404.html;
location = /40x.html {
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
}
}
# Settings for a TLS enabled server.
#
# server {
# listen 443 ssl http2 default_server;
# listen [::]:443 ssl http2 default_server;
# server_name _;
# root /usr/share/nginx/html;
#
# ssl_certificate "/etc/pki/nginx/server.crt";
# ssl_certificate_key "/etc/pki/nginx/private/server.key";
# ssl_session_cache shared:SSL:1m;
# ssl_session_timeout 10m;
# ssl_ciphers HIGH:!aNULL:!MD5;
# ssl_prefer_server_ciphers on;
#
# # Load configuration files for the default server block.
# include /etc/nginx/default.d/*.conf;
#
# location / {
# }
#
# error_page 404 /404.html;
# location = /40x.html {
# }
#
# error_page 500 502 503 504 /50x.html;
# location = /50x.html {
# }
# }
}
命令操作
[root@92fuge ~]# grep -Ev '#|^#39; /etc/nginx/nginx.conf
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log;
pid /run/nginx.pid;
include /usr/share/nginx/modules/*.conf;
events {
worker_connections 1024;
}
http {
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
types_hash_max_size 2048;
include /etc/nginx/mime.types;
default_type application/octet-stream;
include /etc/nginx/conf.d/*.conf;
server {
listen 80 default_server;
listen [::]:80 default_server;
server_name _;
root /usr/share/nginx/html;
include /etc/nginx/default.d/*.conf;
location / {
}
error_page 404 /404.html;
location = /40x.html {
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
}
}
}
示例2#在指定文件中查找特定字符串 [root@CentOS ~]# grep root /etc/passwd #结合管道一起使用 [root@CentOS ~]# cat /etc/passwd | grep root #将显示符合条件的内容所在的行号 [root@CentOS ~]# grep -n root /etc/passwd #在nginx.conf查找包含listen的行号打印出来 [root@CentOS conf]# grep listen nginx.conf #结合管道联合使用,其中/sbin/ifconfig 表示查看当前系统的网络配置信息,后查找包含“inetaddr"的字符串,第2行为查找的结果 [root@CentOS etc]# cat filel [root@CentOS etc]# grep var filel [root@CentOS etc]# grep -v var filel #显示行号 [root@CentOS etc]# grep -n var filel [root@CentOS nginx]# /sbin/ifconfig | grep "inet addr" #综合使用nbsp;grep magic /usr/src/linux/Documentation/* | tail
#查看文件内容
[root@CentOS etc]# cat test.txt
#查找指定字符串,此时是区分大小写
[root@CentOS etc]# grep uuid test.txt
[root@CentOS etc]# grep UUID test.txt
#不区分大小写查找指定字符串
[root@92fuge etc]# grep -i uuid test.txt
#列出匹配字符串的文件名
[root@92fuge etc]# grep -l UUID test.txt
[root@92fuge etc]# grep -L UUID test.txt
#列出不匹配字符串的文件名
[root@92fuge etc]# grep -L uuid test.txt
#匹配整个单词
[root@92fuge etc]# grep -W UU test.txt
[root@92fuge etc]# grep -W UUID test.txt
#除了显示匹配的行,分别显示该行上下文的N行
[root@92fuge etc]# grep -C1 UUID test.txt
[root@92fuge etc]# grep -n -E "^[a-z]+" test.txt
[root@92fuge etc]# grep -n -E "^[^a-z]+" test.txt
#按正则表达式查找指定字符串
[root@92fuge etc]# cat my.cnf
#按正则表达式查找
[root@92fuge etc]# grep -E "datadir|socket"my.cnf
[root@92fuge etc]# grep mysql my.cnf
#结合管道一起使用
[root@92fuge etc]# grep mysql my.cnf | grep datadir
#递归查找
[root@92fuge etc]# grep -r var .|head -3
反向查找,文件名中包含test 的文件中不包含test 的行grep -v test*
例:在文件kkk中搜索匹配字符“test file”。
[root@rhel ~]# grep ‘test file’ kkk test file
例:在文件aa中显示所有包含至少有5个连续小写字符的行数据内容。
[root@92fuge ~]# grep ‘[a-z]\{5\}’ aa aaaaa aaaaaa
例:在/root/aa文件中找出以b开头的行内容。
[root@92fuge ~]# grep ^b /root/aa bbb
例:在/root/aa文件中输出不是以b开头的行内容。
[root@92fuge ~]# grep -v ^b /root/aa aaaaa AAAAA BBB aaaaaa
例:在/root/kkk文件中输出以le结尾的行内容。
[root@92fuge ~]# grep le$ /root/kkk test file
在stdout1.log文件中查找有’exception’的行。
grep ‘exception’ stdout1.log
在stdout1.log文件中查找有’exception’的行的数目。
grep -c ‘exception’ stdout1.log
grep不显示本身进程
ps aux|grep \[s]sh
ps aux | grep ssh | grep -v “grep”
输出ip地址
ifconfig eth0|grep -E “([0-9]{1,3}\.){3}[0-9]”
显示当前目录下面以.txt 结尾的文件中的所有包含每个字符串至少有7个连续小写字符的字符串的行
grep ‘[a-z]\{7\}’ *.txt
日志文件过大,不好查看,我们要从中查看自己想要的内容,或者得到同一类数据,比如说没有404日志信息的
grep ‘.’ access1.log|grep -Ev ‘404’ > access2.log
grep ‘.’ access1.log|grep -Ev ‘(404|/photo/|/css/)’ > access2.log
grep ‘.’ access1.log|grep -E ‘404’ > access2.log
二 、grep支持丰富的正则表达式,常见的正则元字符含义表
grep支持丰富的正则表达式,常见的正则元字符含义表 grep正则参数说明 参数 说明 ^ 指定匹配字符串的行首nbsp; 指定匹配字符串的结尾
* 表示0个以上的字符
+ 表示1个以上的字符
\ 去掉指定字符的特殊含义
^ 指定行的开始
nbsp; 指定行的结束
. 匹配一个非换行符的字符
* 匹配零个或多个先前字符
[] 匹配一个指定范围内的字符
[^] 匹配一个不在指定范围内的字符
\(..\) 标记匹配字符
< 指定单词的开始
> 指定单词的结束
X{m} 重复字符X,m次 如:'0\{5\}'匹配包含5个o的行。
X{m,} 重复字符X,至少m次 如:'o\{5,\}'匹配至少有5个o的行。
X{m,n} 重复字符X,至少m次,不多于n次 如:'o\{5,10\}'匹配5--10个o的行。
W 匹配文字和数字字符,也就是[A-Za-z0-9]
b 单词锁定符
+ 匹配一个或多个先前的字符
? 匹配零个或多个先前的字符
a|b|c 匹配a或b或c
() 分组符号
[:alnum:] 文字数字字符
[:alpha:] 文字字符
[:digit:] 数字字符
[:graph:] 非空格、控制字符
[:lower:] 小写字符
[:cntrl:] 控制字符
[:print:] 非空字符(包括空格)
[:punct:] 标点符号
[:space:] 所有空白字符(新行,空格,制表符)
[:upper:] 大写字符
[:xdigit:] 十六进制数字(0-9,a-f,A-F)
匹配的实例:grep -c "48" test.txt 统计所有以“48”字符开头的行有多少 grep -i "May" test.txt 不区分大小写查找“May”所有的行) grep -n "48" test.txt 显示行号;显示匹配字符“48”的行及行号,相同于 nl test.txt |grep 48) grep -v "48" test.txt 显示输出没有字符“48”所有的行) grep "471" test.txt 显示输出字符“471”所在的行) grep "48;" test.txt 显示输出以字符“48”开头,并在字符“48”后是一个tab键所在的行 grep "48[34]" test.txt 显示输出以字符“48”开头,第三个字符是“3”或是“4”的所有的行) grep "^[^48]" test.txt 显示输出行首不是字符“48”的行) grep "[Mm]ay" test.txt 设置大小写查找:显示输出第一个字符以“M”或“m”开头,以字符“ay”结束的行) grep "K…D" test.txt 显示输出第一个字符是“K”,第二、三、四是任意字符,第五个字符是“D”所在的行) grep "[A-Z][9]D" test.txt 显示输出第一个字符的范围是“A-D”,第二个字符是“9”,第三个字符的是“D”的所有的行 grep "[35]..1998" test.txt 显示第一个字符是3或5,第二三个字符是任意,以1998结尾的所有行 grep "4/{2,/}" test.txt 模式出现几率查找:显示输出字符“4”至少重复出现两次的所有行 grep "9/{3,/}" test.txt 模式出现几率查找:显示输出字符“9”至少重复出现三次的所有行 grep "9/{2,3/}" test.txt 模式出现几率查找:显示输出字符“9”重复出现的次数在一定范围内,重复出现2次或3次所有行 grep -n "^quot; test.txt 显示输出空行的行号
ls -l |grep "^d" 如果要查询目录列表中的目录 同:ls -d *
ls -l |grep "^d[d]" 在一个目录中查询不包含目录的所有文件
ls -l |grpe "^d…..x..x" 查询其他用户和用户组成员有可执行权限的目录集合
更多的例子:
搜索有the的行,并输出行号
$grep -n 'the' regular_express.txt
搜 索没有the的行,并输出行号
$grep -nv 'the' regular_express.txt
利 用[]搜索集合字符
[] 表示其中的某一个字符 ,例如[ade] 表示a或d或e
woody@xiaoc:~/tmpnbsp;grep -n 't[ae]st' regular_express.txt
8:I can't finish the test.
9:Oh! the soup taste good!
可以用^符号做[]内的前缀,表示除[]内的字符之外的字 符。
比如搜索oo前没有g的字符串所在的行. 使用 '[^g]oo' 作搜索字符串
woody@92fuge:~/tmpnbsp;grep -n '[^g]oo' regular_express.txt
2:apple is my favorite food.
3:Football game is not use feet only.
18:google is the best tools for search keyword.
19:goooooogle yes!
内可以用范围表示,比如[a-z] 表示小写字母,[0-9] 表示0~9的数字, [A-Z] 则是大写字母们。[a-zA-Z0-9]表示所有数字与英文字符。 当然也可以配合^来排除字符。
搜索包含数字的行
woody@92fuge:~/tmpnbsp;grep -n '[0-9]' regular_express.txt
5:However ,this dress is aboutnbsp;3183 dollars.
15:You are the best is menu you are the no.1.
行首与行尾字符 ^ $. ^ 表示行的开头,$表示行的结尾( 不是字符,是位置)那么‘^$’ 就表示空行,因为只有行首和行尾。
这里^与[]里面使用的^意义不同。它表示^后面的串是在行的开头。
比如搜索the在开头的行
woody@92fuge:~/tmpnbsp;grep -n '^the' regular_express.txt
12:the symbol '*' is represented as star.
搜索以小写字母开头的行
woody@92fuge:~/tmpnbsp;grep -n '^[a-z]' regular_express.txt
2:apple is my favorite food.
4:this dress doesn't fit me.
10:motorcycle is cheap than car.
12:the symbol '*' is represented as star.
18:google is the best tools for search keyword.
19:goooooogle yes!
20:go! go! Let's go.
woody@92fuge:~/tmp$
搜索开头不是英文字母的行
woody@92fuge:~/tmpnbsp;grep -n '^[^a-zA-Z]' regular_express.txt
1:"Open Source" is a good mechanism to develop programs.
21:#I am VBird
woody@92fuge:~/tmp$
$表示它前面的串是在行的结尾,比如 '/.' 表示 . 在一行的结尾
搜索末尾是.的行
woody@92fuge:~/tmpnbsp;grep -n '/.
#39; regular_express.txt //. 是正则表达式的特殊符号,所以要用/转义
1:"Open Source" is a good mechanism to develop programs.
2:apple is my favorite food.
3:Football game is not use feet only.
4:this dress doesn't fit me.
5:However ,this dress is aboutnbsp;3183 dollars.
6:GNU is free air not free beer.
注意在MS的系统下生成的文本文件,换行会加上一个 ^M 字符。所以最后的字符会是隐藏的^M ,在处理Windows
下面的文本时要特别注意!
可以用cat dos_file | tr -d '/r' > unix_file 来删除^M符号。 ^M==/r
那么'^#39; 就表示只有行首行尾的空行拉!
搜索空行
woody@92fuge:~/tmpnbsp;grep -n '^
#39; regular_express.txt
22:
23:
woody@92fuge:~/tmp$
搜索非空行
woody@92fuge:~/tmpnbsp;grep -vn '^
#39; regular_express.txt
1:"Open Source" is a good mechanism to develop programs.
2:apple is my favorite food.
3:Football game is not use feet only.
4:this dress doesn't fit me.------本页内容已结束,喜欢请分享------
感谢您的来访,获取更多精彩文章请收藏本站。









暂无评论内容